Sep 1
File systems with a billion files, archiving and compression
about
This continues the billion file file systems blog posts (tag); the first post has an introduction and a Table of Contents.
Previously, we looked at populating file systems.
The file systems / drive images are a bit unwieldy and tricky to copy and move around efficiently. If we archive and compress them, they’ll be much smaller and easier to move around.
This is a long post; sorry not sorry.
goals and theories to test
- reproduce (and add to) the archive stats from Lars Wirzenius’ blog post
- recompressing – like, decompressing the
gzip -1output, and piping that into another compressor – could speed things up. The cpu impact of decompression could outweigh the other resources saved. - do ext2 and ext4 file systems produce file systems that compress better or worse? how about the different generators?
- using tar’s sparse file handling should help with compression
- there are a lot of compressors; let’s figure out the interesting ones
overall notes
Notes:
- compressed sizes are as reported by
pv, which uses e.g. gibibytes, more like base 1024 than 1000. If I’m not measuring numbers, I’ll probably use “gigabytes”, from habit. - the timings are by wall clock, not cpu
- decompression time is measured to
/dev/null, not to a drive
xz – running 5.4.1-0.2, with liblzma 5.4.1. It is not impacted by the 2024-03-29 discovery of an xz backdoor, at least, so far.
- the full
xz -1command:xz -T0 -1 - the full
xz -9command:xz -T3 -M 4GiB -9- I’m using only three threads, on a four-core system, because of memory constraints: this is a 4GiB system, and in practice, each thread uses over a gigabyte of memory.
hardware changes
As mentioned in the parallel multitouch post, one SMR hard drive fell over and its replacement (another arbitrary unused drive off my shelf) was painfully slow, writing at 3-4MiB/s. I’d worked on archiving and compression on the SMR drives before shifting, mounting a network share on a NAS as storage for the Pi. This sped up populating the file systems, but there’s a caveat later.
new, faster media! let’s make those file systems again!
Some timing for generating the file systems into drive images, onto the NAS. Roughly in order of appearance in this post:
| method | time |
|---|---|
| Rust program on ext2 | 12hr48min |
| Rust program on ext4 | 14hr14min |
| multitouch on ext4 | 18hr36m |
| parallel multitouch on ext4 | 7hr4m |
That Rust on ext2 was the fastest generator I’d run, to that point.
Surprisingly, populating ext4 was slower than ext2; they switched places from last time, on the first SMR hard drive I tried.
retracing Wirzenius’ results
Let’s check the numbers from Wirzenius’ blog post. It intended to use ext4, but it was using ext2 (bug, now fixed). To reproduce statistics, we’ll use the Rust program and ext2 for these results. For example, the resulting files would look like 1tb-ext2.img.gz-1.
These are compressing a 1TB file, with 276GB of data reported by du.
| compression | previously | my ext2 compressed size | in bytes | compression | gzip -1 recompression | decompression |
|---|---|---|---|---|---|---|
| gzip -1 | 20546385531 | 18.7GiB | 20066756423 | 4hr22m | 4h10m | 1h49m |
| gzip -9 | 15948883594 | 14.7GiB | 15798444076 | 19hr27m | 19hr13m | 2hr35m |
| xz -1 | 11389236780 | 10.6GiB | 11340387800 | 4hr23m | 4hr6m | 44m38s |
| xz -9 | 10465717256 | 9.6GiB | 10396503772 | 20hr45m | 19hr57m | 44m46s |
| total | 53.6GiB | 49hr | 47hr26m | 5hr52m |
Some notes:
- it looks like decompressing a gzip version, and compressing that output, does save some time, though it’s only 1% to 4%. When on the SMR drives, I’d seen improvements of 10% and more. this is enough for me to skip “compress directly from the raw image file, over the network” from now on.
- the comparative sizes between my results and Wirzenius’ are roughly the same. my compressed images are a bit smaller – between 0.4% and 2.3%. my theory: my image generation ran faster, so the timestamps varied less, and so, compressed better.
onward, to ext4
As mentioned, using ext2 wasn’t intended. As of March 2024, the Linux kernel has deprecated ext2, as it hasn’t handled the Year 2038 Problem.
ext4, rust
I used the observation that gzip decompression paid for itself timewise, compared to network I/O.
| compression | my ext2 compressed size | my ext4 compressed size | in bytes | gzip-1 recompression | decompression |
|---|---|---|---|---|---|
| gzip -1 | 18.7GiB | 25.8GiB | 27676496022 | 4hr25m | 1hr53m |
| gzip -9 | 14.7GiB | 21.7GiB | 23267641548 | 27hr11m | 2hr39m |
| xz -1 | 10.6GiB | 15.4GiB | 16492139376 | 4hr44m | 47m |
| xz -9 | 9.6GiB | 14.3GiB | 15361740048 | 27hr | 51m |
| total | 53.6GiB | 77.2GiB | 63hr20m | 6hr10m |
Comparing against ext2:
- the compressed file sizes: ext4 was larger by an extra 37% to 48%.
- compression time increased, 15% to 42%.
using tar on file systems
The resulting drive images here would be something like 1tb-ext4.img.tar.gz. It’s not archiving the mounted file system, but the drive image.
a sidenote: sparse files
The file systems / drive images are sparse files – while they could hold up to a terabyte, we’ve only written about a quarter of that. When we measure storage used – du -h, instead of ls -h – they only take up the smaller amount. They’re still unwieldy – about 270 gigabytes! – but a full terabyte is worse. The remainder is empty, which we don’t need to reserve space for, and we can (often) skip processing or storing it, with care. But, if anything along the way – operating systems, software, the file system holding the drive image, network protocols – doesn’t support sparse files, or we don’t enable sparse file handling, then it’ll deal with almost four times as much “data.” (Yes, this is ominous foreshadowing.)
The gzip and xz compressors above processed the full, mostly empty, terabyte. Unpacking those, as is, will take up a full terabyte.
The theory: If we archive, then compress them, they’ll be smaller and we can transfer them, preserving sparse files, with less hassle. We can benefit from both sparse file handling, and making it a non-issue.
issue: sparse files on a network share
tar can handle sparse files efficiently. Even without compression, we’d expect tar to read that sparse file, and make a tar file that’s closer to 270 GiB than a terabyte.
An issue here: While the Raspberry Pi, the NAS, and each of their operating systems, can each handle sparse files well, the network share doesn’t – I was using SMB / Samba or the equivalent, not, say, NFS or WebDAV. Writing sparse files works well! Reading sparse files: the network share will send all the zeros over the wire, instead of “hey, there’s a gigabyte of a sparse data gap here”. While that gigabyte of zeros will take only take a few seconds to transfer over gigabit ethernet, we’re dealing with over 700 of them. It adds up.
However, be aware that
--sparseoption may present a serious drawback. Namely, in order to determine the positions of holes in a filetarmay have to read it before trying to archive it, so in total the file may be read twice. This may happen when your OS or your FS does not supportSEEK_HOLE/SEEK_DATAfeature inlseek.
Doing the math, I’d expect tar to take over two hours to get to the point of actually emitting output. While it took over four hours for image.tar to run over the network, that seems uncharitable to measure here, like we’re setting it up to fail. After the initial, slow, tar creation, we’re not working with a bulky sparse file; we can recompress it, and (in theory) see something like what it might look like if we were using another network sharing protocol or a fast local drive.
As a sidenote: Debian includes bsdtar, a port of tar from (I think) FreeBSD; it didn’t detect gaps at all in this context, so the generated tar file was a full terabyte, and the image.tar.gz didn’t save space compared to the image.gz. On a positive note, it can detect gaps on unpacking, if you happened to make a non-sparse tar file and want to preserve the timestamps and other metadata.
tar compression results
To gauge the compression speed, I used, as above, an initial tar.gz file, then decompressed that into a pipe, and recompressed it.
We’ll call the largest entry per column 100% – that’s gzip -1.
| compressor | metric | rust, image | rust, tar | tar saves |
|---|---|---|---|---|
| gzip -1 | space | 25.8GiB, 100% | 22.4GiB, 100% | 3.4GiB, 13% |
| compression time | 4hr25m | 1hr33m | 64% | |
| decompression time | 1hr53m | 37m16s | 67% | |
| gzip -9 | space | 21.7GiB, -15% | 20.9GiB, -6% | 0.8GiB, 3.6% |
| compression time | 27hr11m | 23hr58m | 11% | |
| decompression time | 2hr39m | 36m54s | 77% | |
| xz -1 | space | 15.4GiB, -40% | 15.2GiB, -32% | 0.2GiB, 1.2% |
| compression time | 4hr44m | 2hr26m | 48% | |
| decompression time | 47m | 18m25s | 61% | |
| xz -9 | space | 14.3GiB, -44% | 14.2GiB, -36% | 0.1GiB, 0.6% |
| compression time | 27hr | 23hr33m | 12% | |
| decompression time | 51m | 21m17s | 58% |
In short: Using tar (after the initial network share hurdle) saved resources, both compression time and file size.
more compressors
There’s a trend in gathering compressors, to catch them all be comprehensive. “My Pokemans compressors, let me show you them.” I’m not immune to this, though I showed some restraint.
I tried compressors I was familiar with, and some that came up in discussions, and were already or easily available in Debian and ARM.
issues found: crashes when decompressing
Various compressors were glitchy in the latest OS (bookworm, Debian 12), against storage on the NAS: lzop, pbzip2, pigz, and plzip. They seemed to compress, but then crashed on attempts to decompress. After this, I used checksums to verify the output of decompression, and verified that these were the only compressors with issues. I made a fresh bookworm MicroSD card, and reproduced the issue.
These compressors worked in the previous version (bullseye, Debian 11), against storage on the NAS. They’re marked on the graph with different colors and shapes. I intend to explore the issues further, but in a later, separate blog post.
my method for benchmarking compression
I wrote shell scripts for this. A fun fact: bash doesn’t parse too far ahead when interpreting, so, I was able to edit and reprioritize the next steps while it was running, cheap and dirty.
The form of the scripts evolved as I worked on this; the latest version was DRY’ed up (Don’t Repeat Yourself), and I’ll post it on my Gitlab repo. This should be enough for others to check that, say, I didn’t leave out multithreading for some compression or decompression.
results
I graphed Compression time vs compressed file size, for the ext4 file system made by the Rust program, as a tar file.
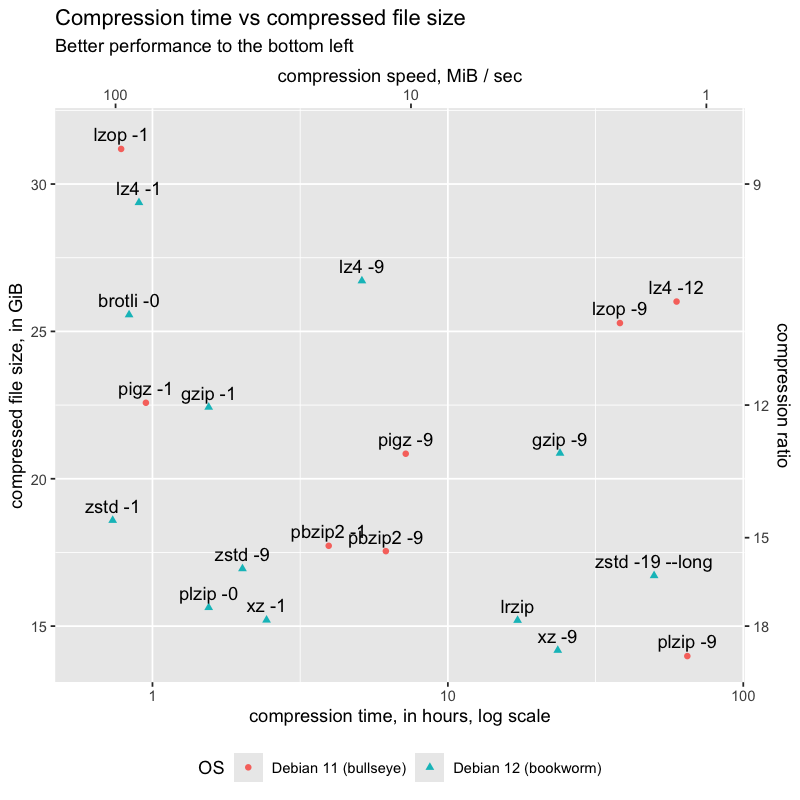
Over on the billion file fs repo:
- the data tables, as CSVs
- graphs including decompression time
- R code for all the graphs
Not included in those tables or graphs:
brotli -11was on track to take 23 days, though larger than xz -9.lrziptook over 22 hours to decompress to stdout, over ten times slower than the next slowest,pbzip2 -9. even on a log scale, it was the only data point in the top half of the graph.
The compressors of interest to me, were the ones with fastest compression and smallest compressed files. From fastest to slowest:
- zstd -1 and -9
- plzip -0 – could replace zstd -9, but was only reliable on bullseye
- xz -1 and -9
- gzip -1 and -9 – just for comparison
To be thorough about the Pareto frontier:
- lzop -1 has potential – a minute faster than zstd -1, but 50% larger, unreliable on bookworm, and four minutes slower on bullseye. (Benchmarking bullseye vs. bookworm is out of scope.)
- plzip -9 offered a bit over 1% space savings over xz -9, but, took 2.6 times as long – 64 hours vs 23 hours
how well do file systems from the different generators compress?
I expected the Rust image to compress worse than multitouch, and I wasn’t sure where parallel multitouch would fit.
Let’s discuss how they lay out the empty files.
generators – Rust
Wirzenius’ Rust program creates the files, in order, one at a time.
Looking at a file system it made, the directory layouts are (roughly, with a caveat):
- 0 to 999/0 to 999/file-1.txt to file-1000000000.txt
generators – multitouch
Multitouch creates the files, in order, 1k at a time. Parallel multitouch makes the directories roughly in order, but slightly interleaved. Both attempt to use consistent timestamps and filenames.
The directory layouts:
- 0001 to 1000/0001 to 1000/0001 to 1000
The relatively shorter file names led to less space usage, before compression.
results
The table of data is in the same place as above; here’s the chart comparing the different generators, for the compressors I decided on above.
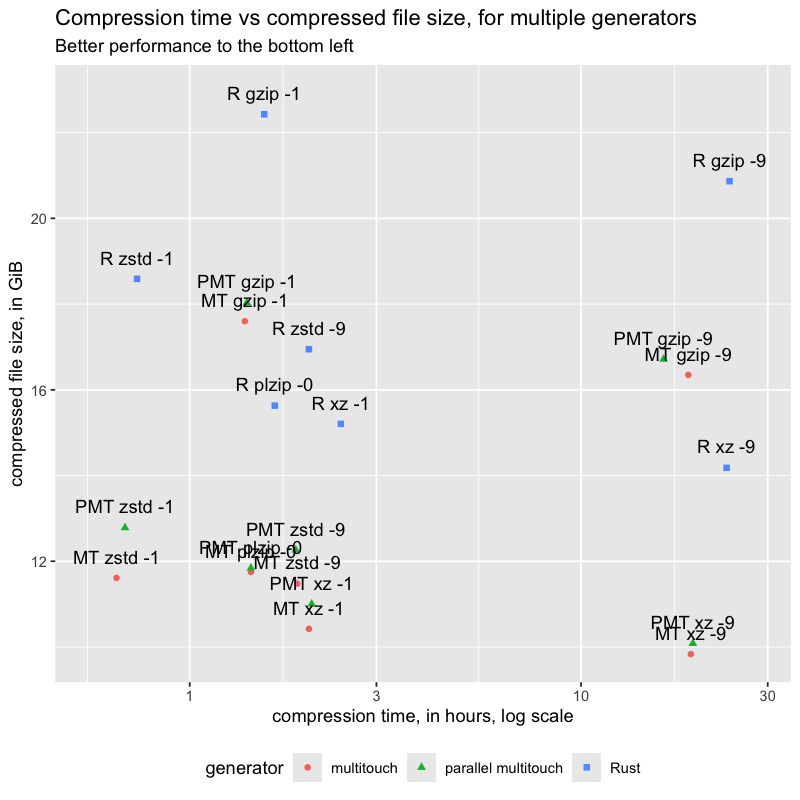
analysis
Looking at the chart, parallel multitouch was a bit worse than multitouch, but both compressed to smaller files compared to the Rust image.
plzip -0 usually, but not always, fit between zstd -1 and xz -1. For multitouch (not parallel), it was larger than zstd -9.
compression on ext4 file systems
| generator | compressor | size | compression time | decompression time |
|---|---|---|---|---|
| Rust | ext4 image, xz -9 | 14.3GiB | 27hr | 51min |
| Rust | ext4 image.tar, xz -9 | 14.2GiB | 23hr33min | 21min |
| multitouch | ext4 image.tar, xz -9 | 9.8GiB | 19hr5m | 18min |
| parallel multitouch | ext4 image.tar, xz -9 | 10.1GiB | 19hr19min | 18min |
overall summary
- decompressing gzip and piping that to other compressors saves some resources
- ext4 drive images were larger than ext2, by an extra 37% to 48%
- tar’s sparse file handling helps with compression time and space
- the compressors I’d recommend: zstd -1 and -9; plzip -0; and xz -1 and -9
- multitouch file systems compress better than the Rust file systems
reference: software versions
These are the versions reported by apt.
For Debian 12, bookworm, the newer release:
- brotli: 1.0.9-2+b6
- gzip: 1.12-1
- lrzip: 0.651-2
- lz4: 1.9.4-1
- xz: 5.4.1-0.2, with liblzma 5.4.1. It is not impacted by the 2024-03-29 discovery of an xz backdoor, at least, so far.
- zstd: 1.5.4+dfsg2-5
Debian 11, bullseye, the older release:
- lzop: 1.04-2
- pbzip2: 1.1.13-1. parallel bzip2
- pigz: 2.6-1. parallel gzip
- plzip: 1.9-1
No Comments
Leave a comment