miscellaneousJust another weblog2024-10-29T01:05:11Zhttps://pronoiac.org/misc/feed/atom/WordPressadmin<![CDATA[Testing new drives]]>https://pronoiac.org/misc/?p=2362024-10-29T01:05:11Z2024-10-29T01:03:21Zabout
I bought some used hard drives, from a vendor that was new to me. I was careful with burn-in and testing, as they were being shipped and deployed remotely. I checked for defects and verified capacity. Testing quickly was important, so I could return something that wasn’t working, and get a replacement.
checking for defects
Most drives have SMART diagnostics built-in. It’s a good first pass, requiring little CPU or I/O from the system.
Using an external USB enclosure, and a Linux system, I ran smartctl to test them. I ran smartctl --scan-open to detect the device and type. Of the SMART tests:
conveyance wasn’t available.
short was quick, a few minutes.
long took around 10 hours.
I can’t find my references for parsing the results; perhaps refer to the Wikipedia page.
Of the three drives, one wasn’t recognized. I plugged it in internally; it was recognized, though it yielded errors in the system logs, and smartctl was unable to start any tests. I returned this one drive for replacement, without issue.
verifying capacity
Or, Checking for counterfeits, bootlegs, and fakes
An issue mostly seen with flash drives: scammy, dodgy firmware lets it claim to have a multiple of its real capacity. If you try writing beyond its real capacity, it could:
quietly discard the data
quietly loop back and overwrite earlier data
badblocks is a classic tool for testing drives – however, it was first built for floppy disks. For the nondestructive mode, it would notice the first one (discarding data) but not the second (wrap around to earlier data). The Arch Linux wiki page for badblocks has a suggestion about using a crypto layer above the device.
I’m largely working from a Synology NAS. It lacks cryptsetup, and I’m not going to investigate how to install it, but the idea is sound:
Using an encryption key, we’ll fill the drive with encrypted zeroes. This would be ordering-sensitive – one can’t start decrypting from the middle. Then we’ll decrypt, starting from the beginning, and count how many zeroes we get back from the drive.
“In CBC mode, each block of plaintext is XORed with the previous ciphertext block before being encrypted. This way, each ciphertext block depends on all plaintext blocks processed up to that point.”
Writing encrypted zeroes
Note: this can destroy any data on a drive, so check and double-check the device, sdq on mine. If it breaks, you keep both pieces.
This quick-and-dirty attempt worked quickly enough on my Synology NAS:
date
(for i in $(seq 800); do
cat /dev/zero | head -c 10000000000
>&2 printf "."
done) | \
openssl aes256 -pass "pass:testing" > \
/dev/sdq
date
That writes 800 x 10GiB chunks, for a total of 8TiB. It prints “.” every chunk, about one a minute.
There’s some difference between that and 8TB, due to base-10 terabytes vs base-2 tebibytes, but this ruled out that it was really a 1TB drive, handling my concern.
Side notes
Performance
My first attempt at reading zeroes involved xxd -a, which would essentially hexdump one line of zeroes, and skip other all-zero rows. I estimated the rate as under 1/10th the writing speed.
Hardware acceleration for aes 256 is common, along with Linux kernel support; I don’t think this method takes advantage. Adding -evp might do the trick though.
why not use pv on the Synology?
I would have loved to use pv – pipe viewer – for a handy progress meter and estimate for how long it would take, but it wasn’t readily available for my NAS.
Raspberry Pi notes
Side note: I tried this on my Raspberry Pi 4. I was able to use pv here for a nifty progress meter, get an ETA, etc. However, it ran at something like 1/4 the speed – unoptimized openssl? – so, non-starter. openssl required -md -md5 to accept the password; that’s deprecated. For what I’m doing, I didn’t have to worry about zeroes falling into the wrong hands.
Other software for this
I didn’t use these, but they’re likely better-put-together and more usable than my quick draft above.
“F3 stands for f, or Fight Fake Flash.” Github repo, docs – available on several platforms.
]]>0admin<![CDATA[File systems with a billion files, archiving and compression]]>https://pronoiac.org/misc/?p=2252024-09-08T02:02:24Z2024-09-02T00:27:22Zabout
The file systems / drive images are a bit unwieldy and tricky to copy and move around efficiently. If we archive and compress them, they’ll be much smaller and easier to move around.
recompressing – like, decompressing the gzip -1 output, and piping that into another compressor – could speed things up. The cpu impact of decompression could outweigh the other resources saved.
do ext2 and ext4 file systems produce file systems that compress better or worse? how about the different generators?
using tar’s sparse file handling should help with compression
there are a lot of compressors; let’s figure out the interesting ones
overall notes
Notes:
compressed sizes are as reported by pv, which uses e.g. gibibytes, more like base 1024 than 1000.
If I’m not measuring numbers, I’ll probably use “gigabytes”, from habit.
the timings are by wall clock, not cpu
decompression time is measured to /dev/null, not to a drive
xz – running 5.4.1-0.2, with liblzma 5.4.1. It is not impacted by the 2024-03-29 discovery of an xz backdoor, at least, so far.
the full xz -1 command: xz -T0 -1
the full xz -9 command: xz -T3 -M 4GiB -9
I’m using only three threads, on a four-core system, because of memory constraints: this is a 4GiB system, and in practice, each thread uses over a gigabyte of memory.
hardware changes
As mentioned in the parallel multitouch post, one SMR hard drive fell over and its replacement (another arbitrary unused drive off my shelf) was painfully slow, writing at 3-4MiB/s. I’d worked on archiving and compression on the SMR drives before shifting, mounting a network share on a NAS as storage for the Pi. This sped up populating the file systems, but there’s a caveat later.
new, faster media! let’s make those file systems again!
Some timing for generating the file systems into drive images, onto the NAS.
Roughly in order of appearance in this post:
method
time
Rust program on ext2
12hr48min
Rust program on ext4
14hr14min
multitouch on ext4
18hr36m
parallel multitouch on ext4
7hr4m
That Rust on ext2 was the fastest generator I’d run, to that point.
Surprisingly, populating ext4 was slower than ext2; they switched places from last time, on the first SMR hard drive I tried.
retracing Wirzenius’ results
Let’s check the numbers from Wirzenius’ blog post. It intended to use ext4, but it was using ext2 (bug, now fixed). To reproduce statistics, we’ll use the Rust program and ext2 for these results. For example, the resulting files would look like 1tb-ext2.img.gz-1.
These are compressing a 1TB file, with 276GB of data reported by du.
compression
previously
my ext2 compressed size
in bytes
compression
gzip -1 recompression
decompression
gzip -1
20546385531
18.7GiB
20066756423
4hr22m
4h10m
1h49m
gzip -9
15948883594
14.7GiB
15798444076
19hr27m
19hr13m
2hr35m
xz -1
11389236780
10.6GiB
11340387800
4hr23m
4hr6m
44m38s
xz -9
10465717256
9.6GiB
10396503772
20hr45m
19hr57m
44m46s
total
53.6GiB
49hr
47hr26m
5hr52m
Some notes:
it looks like decompressing a gzip version, and compressing that output, does save some time, though it’s only 1% to 4%. When on the SMR drives, I’d seen improvements of 10% and more. this is enough for me to skip “compress directly from the raw image file, over the network” from now on.
the comparative sizes between my results and Wirzenius’ are roughly the same. my compressed images are a bit smaller – between 0.4% and 2.3%. my theory: my image generation ran faster, so the timestamps varied less, and so, compressed better.
I used the observation that gzip decompression paid for itself timewise, compared to network I/O.
compression
my ext2 compressed size
my ext4 compressed size
in bytes
gzip-1 recompression
decompression
gzip -1
18.7GiB
25.8GiB
27676496022
4hr25m
1hr53m
gzip -9
14.7GiB
21.7GiB
23267641548
27hr11m
2hr39m
xz -1
10.6GiB
15.4GiB
16492139376
4hr44m
47m
xz -9
9.6GiB
14.3GiB
15361740048
27hr
51m
total
53.6GiB
77.2GiB
63hr20m
6hr10m
Comparing against ext2:
the compressed file sizes: ext4 was larger by an extra 37% to 48%.
compression time increased, 15% to 42%.
using tar on file systems
The resulting drive images here would be something like 1tb-ext4.img.tar.gz. It’s not archiving the mounted file system, but the drive image.
a sidenote: sparse files
The file systems / drive images are sparse files – while they could hold up to a terabyte, we’ve only written about a quarter of that. When we measure storage used – du -h, instead of ls -h – they only take up the smaller amount. They’re still unwieldy – about 270 gigabytes! – but a full terabyte is worse. The remainder is empty, which we don’t need to reserve space for, and we can (often) skip processing or storing it, with care. But, if anything along the way – operating systems, software, the file system holding the drive image, network protocols – doesn’t support sparse files, or we don’t enable sparse file handling, then it’ll deal with almost four times as much “data.” (Yes, this is ominous foreshadowing.)
The gzip and xz compressors above processed the full, mostly empty, terabyte.
Unpacking those, as is, will take up a full terabyte.
The theory: If we archive, then compress them, they’ll be smaller and we can transfer them, preserving sparse files, with less hassle.
We can benefit from both sparse file handling, and making it a non-issue.
issue: sparse files on a network share
tarcan handle sparse files efficiently. Even without compression, we’d expect tar to read that sparse file, and make a tar file that’s closer to 270 GiB than a terabyte.
An issue here: While the Raspberry Pi, the NAS, and each of their operating systems, can each handle sparse files well, the network share doesn’t – I was using SMB / Samba or the equivalent, not, say, NFS or WebDAV. Writing sparse files works well! Reading sparse files: the network share will send all the zeros over the wire, instead of “hey, there’s a gigabyte of a sparse data gap here”. While that gigabyte of zeros will take only take a few seconds to transfer over gigabit ethernet, we’re dealing with over 700 of them. It adds up.
However, be aware that --sparse option may present a serious drawback.
Namely, in order to determine the positions of holes in a file tar may have to read it before trying to archive it, so in total the file may be read twice.
This may happen when your OS or your FS does not support SEEK_HOLE/SEEK_DATA feature in lseek.
Doing the math, I’d expect tar to take over two hours to get to the point of actually emitting output.
While it took over four hours for image.tar to run over the network, that seems uncharitable to measure here, like we’re setting it up to fail.
After the initial, slow, tar creation, we’re not working with a bulky sparse file;
we can recompress it, and (in theory) see something like what it might look like if we were using another network sharing protocol or a fast local drive.
As a sidenote: Debian includes bsdtar, a port of tar from (I think) FreeBSD; it didn’t detect gaps at all in this context, so the generated tar file was a full terabyte, and the image.tar.gz didn’t save space compared to the image.gz. On a positive note, it can detect gaps on unpacking, if you happened to make a non-sparse tar file and want to preserve the timestamps and other metadata.
tar compression results
To gauge the compression speed, I used, as above, an initial tar.gz file, then decompressed that into a pipe, and recompressed it.
We’ll call the largest entry per column 100% – that’s gzip -1.
compressor
metric
rust, image
rust, tar
tar saves
gzip -1
space
25.8GiB, 100%
22.4GiB, 100%
3.4GiB, 13%
compression time
4hr25m
1hr33m
64%
decompression time
1hr53m
37m16s
67%
gzip -9
space
21.7GiB, -15%
20.9GiB, -6%
0.8GiB, 3.6%
compression time
27hr11m
23hr58m
11%
decompression time
2hr39m
36m54s
77%
xz -1
space
15.4GiB, -40%
15.2GiB, -32%
0.2GiB, 1.2%
compression time
4hr44m
2hr26m
48%
decompression time
47m
18m25s
61%
xz -9
space
14.3GiB, -44%
14.2GiB, -36%
0.1GiB, 0.6%
compression time
27hr
23hr33m
12%
decompression time
51m
21m17s
58%
In short:
Using tar (after the initial network share hurdle) saved resources, both compression time and file size.
more compressors
There’s a trend in gathering compressors, to catch them all be comprehensive. “My Pokemans compressors, let me show you them.” I’m not immune to this, though I showed some restraint.
I tried compressors I was familiar with, and some that came up in discussions, and were already or easily available in Debian and ARM.
issues found: crashes when decompressing
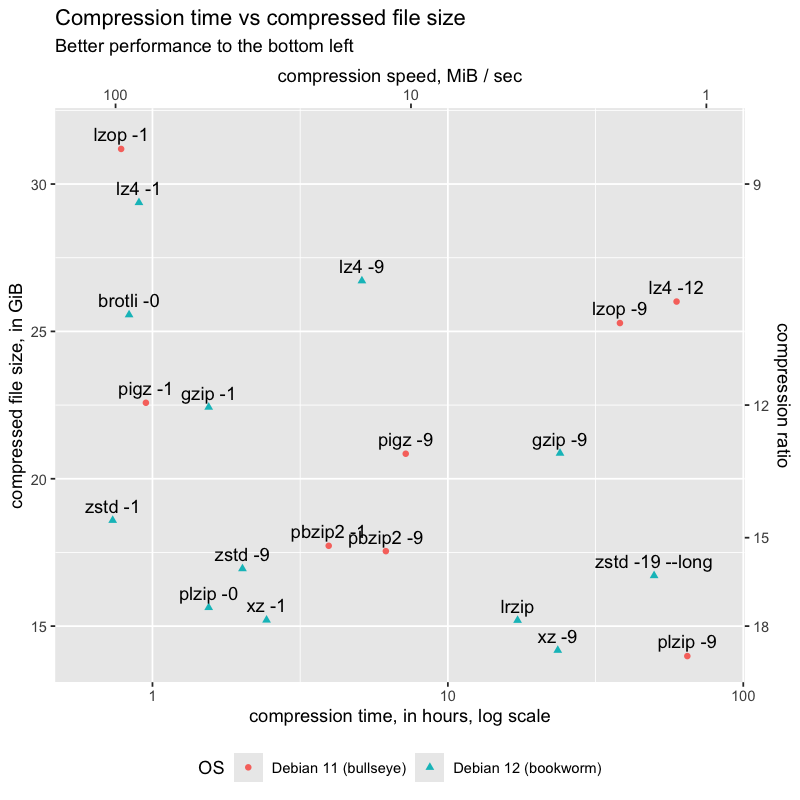
Various compressors were glitchy in the latest OS (bookworm, Debian 12), against storage on the NAS: lzop, pbzip2, pigz, and plzip. They seemed to compress, but then crashed on attempts to decompress. After this, I used checksums to verify the output of decompression, and verified that these were the only compressors with issues. I made a fresh bookworm MicroSD card, and reproduced the issue.
These compressors worked in the previous version (bullseye, Debian 11), against storage on the NAS.
They’re marked on the graph with different colors and shapes.
I intend to explore the issues further, but in a later, separate blog post.
my method for benchmarking compression
I wrote shell scripts for this. A fun fact: bash doesn’t parse too far ahead when interpreting, so, I was able to edit and reprioritize the next steps while it was running, cheap and dirty.
The form of the scripts evolved as I worked on this; the latest version was DRY’ed up (Don’t Repeat Yourself), and I’ll post it on my Gitlab repo. This should be enough for others to check that, say, I didn’t leave out multithreading for some compression or decompression.
results
I graphed Compression time vs compressed file size, for the ext4 file system made by the Rust program, as a tar file.
brotli -11 was on track to take 23 days, though larger than xz -9.
lrzip took over 22 hours to decompress to stdout, over ten times slower than the next slowest, pbzip2 -9. even on a log scale, it was the only data point in the top half of the graph.
The compressors of interest to me, were the ones with fastest compression and smallest compressed files. From fastest to slowest:
zstd -1 and -9
plzip -0 –
could replace zstd -9, but was only reliable on bullseye
lzop -1 has potential – a minute faster than zstd -1, but 50% larger, unreliable on bookworm, and four minutes slower on bullseye. (Benchmarking bullseye vs. bookworm is out of scope.)
plzip -9 offered a bit over 1% space savings over xz -9, but, took 2.6 times as long – 64 hours vs 23 hours
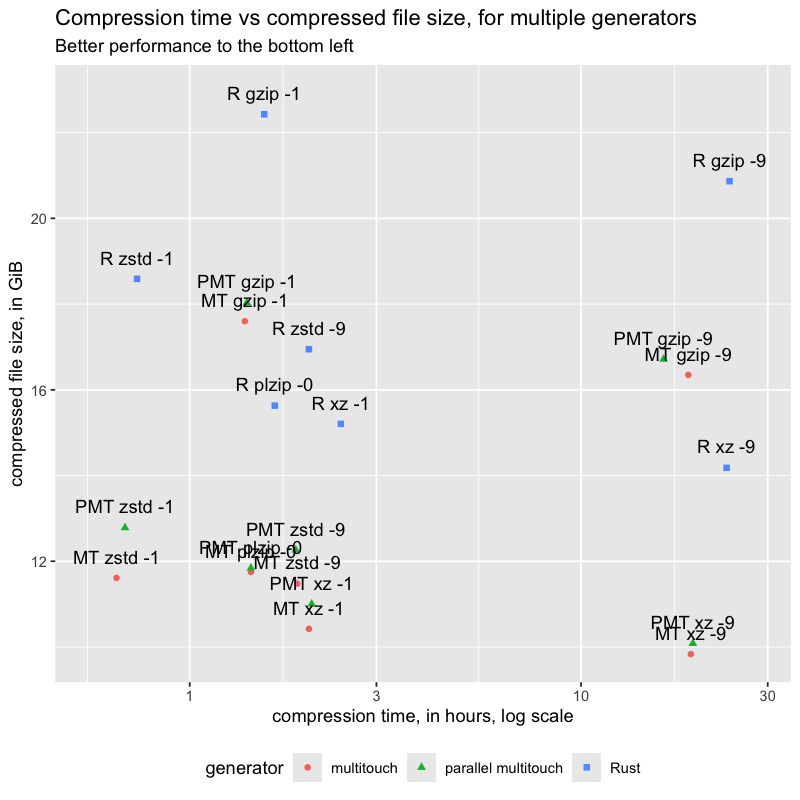
how well do file systems from the different generators compress?
I expected the Rust image to compress worse than multitouch, and I wasn’t sure where parallel multitouch would fit.
Looking at a file system it made, the directory layouts are (roughly, with a caveat):
0 to 999/0 to 999/file-1.txt to file-1000000000.txt
generators – multitouch
Multitouch creates the files, in order, 1k at a time. Parallel multitouch makes the directories roughly in order, but slightly interleaved. Both attempt to use consistent timestamps and filenames.
The directory layouts:
0001 to 1000/0001 to 1000/0001 to 1000
The relatively shorter file names led to less space usage, before compression.
results
The table of data is in the same place as above; here’s the chart comparing the different generators, for the compressors I decided on above.
analysis
Looking at the chart, parallel multitouch was a bit worse than multitouch, but both compressed to smaller files compared to the Rust image.
plzip -0 usually, but not always, fit between zstd -1 and xz -1.
For multitouch (not parallel), it was larger than zstd -9.
compression on ext4 file systems
generator
compressor
size
compression time
decompression time
Rust
ext4 image, xz -9
14.3GiB
27hr
51min
Rust
ext4 image.tar, xz -9
14.2GiB
23hr33min
21min
multitouch
ext4 image.tar, xz -9
9.8GiB
19hr5m
18min
parallel multitouch
ext4 image.tar, xz -9
10.1GiB
19hr19min
18min
overall summary
decompressing gzip and piping that to other compressors saves some resources
ext4 drive images were larger than ext2, by an extra 37% to 48%
tar’s sparse file handling helps with compression time and space
the compressors I’d recommend: zstd -1 and -9; plzip -0; and xz -1 and -9
multitouch file systems compress better than the Rust file systems
reference: software versions
These are the versions reported by apt.
For Debian 12, bookworm, the newer release:
brotli: 1.0.9-2+b6
gzip: 1.12-1
lrzip: 0.651-2
lz4: 1.9.4-1
xz: 5.4.1-0.2, with liblzma 5.4.1.
It is not impacted by the 2024-03-29 discovery of an xz backdoor, at least, so far.
zstd: 1.5.4+dfsg2-5
Debian 11, bullseye, the older release:
lzop: 1.04-2
pbzip2: 1.1.13-1.
parallel bzip2
pigz: 2.6-1.
parallel gzip
plzip: 1.9-1
]]>0admin<![CDATA[File systems with a billion files, making forests, parallel multitouch]]>https://pronoiac.org/misc/?p=2132024-06-24T06:15:44Z2024-06-24T06:09:49Zabout
Making file systems with a billion files is interesting for feeling out scaling issues.
While working on the upcoming archiving and compression post, with various obstacles, yet another method for making those file systems came to mind: running multiple multitouch methods in parallel. Spoilers: It’s the fastest method for making file systems with a billion files that I’ve run.
hardware
I worked from a Raspberry Pi 4, with 4 GB RAM, running Debian 12 (bookworm).
It has four cores.
For storage – this is new – I connected the Pi to my NAS.
environmental changes
While gathering data for the upcoming archiving and compression post, the first hard drive, a 2017-era Seagate USB hard drive, flaked out.
When connected to my Pi, the drive would go offline, with kernel log messages involving “over-current change” – which might point at the power supply for the Pi.
This hard drive’s shelved for now.
The second spare drive I reached for was a 2023-era WD USB hard drive.
It was also an SMR drive, and the performance was surprisingly awful.
As in, I went looking for malware.
Perhaps it just needs some time for internal remapping and housekeeping, but it’s off to the side for now.
I connected the Pi to my NAS, with redundant CMR hard drives, over Gigabit Ethernet.
new repo
Before, I’d placed a few scripts in a fork for create-empty-files; I’m adding more and it feels like tangential clutter. So, I started a billion-file-fs repo. I plan to put everything in this post there; see the scripts directory.
parallel multitouch
I realized I could run multiple multitouch in parallel.
There’s a rule of thumb for parallel processes: the number of processor cores, plus one. I benchmarked with a million files, and one to ten processes; the peak was five, matching that expectation.
processes
time
files / sec
1
1m57s
8490
2
1m5s
15200
3
50s
19700
4
45.2s
22000
5
43.7s
22800
6
44.1s
22600
7
45.0s
22100
8
44.8s
22200
9
44.8s
22200
10
45.0s
22100
how did it do?
It populated a billion files in under seven hours, a new personal record!
Here are how the fastest generators ran, against NAS storage:
method
time
space used
files/sec
multitouch on ext4
18hr36min
260GB
14900
Rust program on ext4
14hr14min
278GB
19500
Rust program on ext2
12hr48min
276GB
21700
parallel multitouch on ext4
6hr41min
260GB
41500
Against the first USB drive, Rust & ext2 was slower than ext4.
They switched places here, which surprised me.
what’s next?
Probably archiving and compression – it’s already much longer, with graphs.
]]>0admin<![CDATA[Time Machine, migrating from a network share to an external drive]]>https://pronoiac.org/misc/?p=2062024-04-15T03:46:59Z2024-04-15T03:44:58Zwhy?
I was restoring an entire computer, and restoring from my network share on a NAS wouldn’t work: it would quietly hang, a day in. Copying the backups to an external drive and restoring from that worked.
This is the simpler migration. I’m planning to post the opposite direction separately.
scary warnings (haha, but seriously)
I started writing these for the “external drive to network share” migration, but, uh.
Look, doing this still feels a bit cavalier to me, I guess.
These processes were largely worked out with HFS+ backups; I haven’t walked through these with APFS backups.
These (mostly) worked for me, but they are very much not officially supported.
There’s a lot of context, and I’ve likely forgotten details; it’s been a year or two. This is still kind of a rough draft. I’ll try to highlight rough bits and gaps.
Newer versions of the OS might be more protective of letting you access these backups, even as root.
caveats
I think the external drive won’t be encrypted, even if the sparse bundle on the network share was. I think I managed to get it to start incrementally encrypting the external drive by adding it as a backup location, with encryption, then having it go “oh! ok! got it”.
background
On a network share, Macs use sparse bundles to make something that looks like a Mac disk image, on a network share where the file system is relatively unimportant.
If the Mac can read and write the files within, things like user IDs, permissions, and encryption don’t have to be coordinated across machines.
mounting the source sparse bundle
On the network share, it will be called something like Bob's MacBook.backupbundle or .sparsebundle.
From the Finder, you can “Connect to the server”, go to the network share, select the appropriate sparse bundle, and either double-click it or right-click and “Open” it.
You’ll probably see “Time Machine Backups” as a mounted volume.
file layout for “Time Machine Backups”
Note, this is for an APFS backup.
Backups.backupdb
the name of the Mac, e.g. Bob's MacBook
a series of directories with timestamps, like 2024-04-13-092828
preparing the target external drive
Erase and reformat the external drive.
Label it something distinctive, so you don’t confuse source and target for the copy.
Mount it.
copy data
I’d recommend ethernet instead of wifi.
From a Mac, once the sparse bundle and the external drive are mounted:
# change these as appropriate
input="/Volumes/Time Machine Backups" # sparse bundle
output="/Volumes/Time Machine 2023" # external drive
date; time sudo asr \
--source "$input" \
--target "$output" \
--erase; \
date
It will prompt for:
the sudo password
confirmation of the erasure of the external drive
Part of the process was unmounting the source.
If interrupted, I had to redo:
remount the source
erase and reformat the external drive
example output
Validating target...done
Validating source...done
Erase contents of /dev/disk5 ()? [ny]: y
Validating sizes...done
Restoring ....10....20....30....40....50....60....70....80....90....100
Verifying ....10....20....30....40....50....60....70....80....90....100
Restored target device is /dev/disk5.
This took about 35 hours to process a 4TB drive, 2.6TB used.
]]>0admin<![CDATA[Making file systems with a billion files]]>https://pronoiac.org/misc/?p=1932024-06-24T06:45:18Z2024-03-22T05:45:45Z
this is part 2 – part 1 has an intro and links to the others
I forget where I picked up “forest” as “many files or hardlinks, largely identical”. I hope it’s more useful than confusing. Anyway. Let’s make a thousand thousand thousand files!
file structures
Putting even a million files in a single folder is not recommended. For this, the usual structure:
a thousand level 1 folders, each containing:
a thousand level 2 folders, each containing:
a thousand empty files
various script attempts
These are ordered, roughly, slowest to fastest.
These times were on an ext4 file system.
forest-tar.sh – build a tar.gz with a million files, then unpack it, a thousand times.
makes an effort for consistent timestamps.
forest-multitouch.sh – run touch 0001 ... 1000 in a loop, 1 million times.
makes an effort for consistent timestamps.
More consistent timestamps can lead to better compression of drive images, later.
A friend, Elliot Grafil, suggested that tar would have the benefits of decades of optimization. It’s not a bad showing! zip didn’t fare as well: it was slower, it took more space, and couldn’t be streamed through a pipe like tar.gz can.
the Rust program
Lars Wirzenius’ create-empty-files, with some modifications, was the fastest method.
other file system types are doable, as long as mount recognizes them automatically.
if, when you run this, it takes over a minute to show a progress meter, make sure you’re running on a file system that supports sparse files
about the speed impacts of saving the state
The fastest version was the one where I’d commented out all saving of state. If state were saved to a tmpfs in memory, it slowed down by a third. If state were saved to the internal Micro SD card – and this was my starting point – it ran at about 4% the speed.
file system formats
ext2 vs. ext4
The Rust program was documented as making an ext4 file system, but it was really making an ext2 file system. (I corrected this oversight with merge request #2, merged 2024-03-17.) Switching to an ext4 file system sped up the process by about 45%.
XFS
I didn’t modify the defaults.
After 100 min, it estimated 19 days remaining.
After hitting ctrl-c, it took 20+ min to get a responsive shell.
Unmounting took a few minutes.
btrfs
By default, it stores two copies of metadata.
For speed, my second attempt (“v2”), switched to one copy of metadata:
mkfs.btrfs --metadata single --nodesize 64k -f $image
overall timings for making forests
These are the method timings to create a billion files, slowest to fastest.
method
clock time
files/second
space
shell script: run touch x 1 billion times, ext4
31d (estimated)
375
Rust program, xfs defaults
19d (estimated)
610
Rust program, ext4, state on Micro SD
17 days (estimated)
675
Rust program, btrfs defaults
38hr 50min
7510
781GB
shell script: unzip 1 million files, 1k times, ext4
34 hrs (estimated)
7960
Rust program, ext2
27hr 5min 57s
10250
276GB
Python script, ext4
24hr 11min 43s
11480
275GB
Rust program, ext4, state on /dev/shm
23hr (estimated)
11760
shell script: untar 1 million files, 1k times, ext4
21hr 39min 16s
12830
260GB
shell script: touch 1k files, 1 million times, ext4
]]>0admin<![CDATA[File systems with a billion files, intro / TOC]]>https://pronoiac.org/misc/?p=1882024-09-08T02:15:58Z2024-03-21T04:30:47Zwhat
This is a story about benchmarking and optimization.
Lars Wirzenius blogged about making a file system with a billion empty files.
Working on that scale can make ordinarily quick things very slow – like taking minutes to list folder contents, or delete files.
Initially, I was curious about how well general-purpose compression like gzip would fare with the edge case of gigabytes of zeroes, and then I fell down a rabbit hole.
I found a couple of major speedups, tried a couple of other formats, and tried some other methods for making so many files.
timing
For a brief spoiler: Lars’ best time was about 26 hours. I got their Rust program down to under 16 hours, on a Raspberry Pi. And I managed to get a couple of other methods – shell scripts – to finish in under 24 hours (update!) 7 hours.
sections
I was polishing up a lengthy blog post, and I fell in to what might be a whole other wing of the rabbit hole, and I realized it might be another blog post, or, maybe several posts would be better anyway.
The sections I can see now, I’ll add links as I go, there’s a tag, as well:
when I wrote this, I meant, profiling and optimizing the Rust app. that’s off my list for now.
troubleshooting breakage on Debian 12, bookworm
conclusions?
the hardware I’m using
I worked from a Raspberry Pi 4, with 4 GB RAM, running Debian 12 (bookworm).
The media was a Seagate USB drive, which turned out to be SMR (Shingled Magnetic Recording), and non-optimal when writing a lot of data – probably when writing a gigabyte, and definitely when writing a terabyte.
This is definitely easy to improve upon!
The benefit here: It was handy, and it could crash without inconvenience.
I tried using my Synology NAS, but it never finished a run.
Once, it crashed to the point of having to pull the power cord from the wall.
I think its 2GB of memory wasn’t enough.
I want to keep an eye on domains and their expiration dates without signaling that, avoiding middlemen who would like a signal of interest, to front run the purchase, and auction it off.
This is, to me, surprisingly hard to do.
previously
I kept an eye on various domains I’d like to register, if and when they expire. I set reminders on my calendar to check. With grace periods, it gets more complicated: I’ve seen expiration dates over a month ago, but still blocking a registration.
tips
Don’t go to the domain from your browser. If it works, it could signal interest. If it doesn’t work, it’s not definitive; it might not be registered, the webserver could be down, or it’s being used for email, so the webserver was never connected. Going to the whois.com site is better about getting info like an expiration date.
stages
In a handwaving way, the three stages:
Before their expirations: Monitor a list of domains for expiration dates. This can be somewhat automated, to check weekly or monthly. As that date nears, watch more closely.
After their expirations: Watching the domains as they lapse.
Once they’re available: Buy them. (To be perfectly honest, I haven’t gotten this far.)
before the expiration dates
Happily, there’s a solution built for this. domain-check-2 is a shell script that can read a list of domains from a text file, check their expiration dates, and send email if there’s under a certain number of days remaining. It checks using whois, and I think that this method is safe from would-be domain squatters. I give it a list that looks like this, only my domains:
I’m running it manually, on a weekly basis; I haven’t used the email notification, but looked at the output. The comments, ordering, and exact expiration dates aren’t necessary, but they help me fact-check that it’s working, and they might help my imperfect understanding of the domain lifecycle.
around and after the expiration date
this is much fuzzier
I checked whois (not whois.com) from the command line, and grepped for status or date. If you want to register a domain the day it becomes available, I’d suggest checking the status daily. Knowing when it switches to “pending delete” is important, as that starts a five day timer. Finding that it’s been renewed is another possibility, in which case, update the expiration date in the text file, and go back to step 1.
status
days after expiration
renewable?
website could work
ok
before
yes
yes
renewal grace period
0 to 30* days
yes
maybe
redemption period / restoration grace period
30 to 60 days
yes
no
pending delete
5 day duration
?
no
available
35 to 75, or up to 120 days???
Notes:
Grace period: probably 0 to 30 days. It could be lengthened, to 40 or 90 days, or shortened.
Redemption period: A recovery fee required to renew: $100 to 150. The registrar could put the domain up for auction during this.
Available: Apparently, usually opens sometime between 11am and 2pm Pacific.
Add grace period: People and registries can cancel a domain purchase within five days of purchase. This can be used for domain tasting and domain kiting. This means, if the domain of interest was picked up by someone else, watch it for the next week. Maybe they’ll change their mind and return it.
This timeline can vary by TLD, registrar, and registry.
for further research
Namecheap has an informational page with many TLDs and their grace periods; among other things, it notes that .cm domains – not .com – are sent for deletion upon the expiration date.
2023-06-15 – Alphabet is selling / has sold these assets to Squarespace, I don’t know how long these pages will stay up
Rather than dig into this – there are hundreds of TLDs now! – I’ll punt and say that you should investigate the relevant TLD.
caveats
Don’t rely upon whois.com after the expiration date; aggressive caching could show out-of-date information. Such as, “pending delete” when other sources show it’s been registered for days.
it’s lapsed, buy it!
Apparently, domains usually open sometime between 11am and 2pm Pacific. Logging into your domain registrar of choice, and having funds available, is a good idea, if you want to act quickly.
Honestly, I haven’t gotten as far as “registering a lapsed domain”. The whois.com caching surprised me. This blog post is partially me gathering context and notes, so as and when the next domain of interest nears expiration, I can make exciting new mistakes, rather than repeat old ones.
]]>0admin<![CDATA[Updating an Apple Watch that couldn’t see the Internet]]>https://pronoiac.org/misc/?p=1562023-05-03T23:45:17Z2023-05-03T23:45:17Zwhat
Trying to pair an Apple Watch to a phone, an update was required; upon requesting it, the Apple Watch (through the iPhone) would cancel, reporting:
Unable to check for update, not connected to the Internet
what did not work
rebooting the phone
rebooting the watch
uninstalling the Watch app from my phone – I couldn’t find it
leaving both the watch and the phone on chargers for the duration
what got further
I enabled the iPhone’s hotspot, which disabled its wifi, and attempted the update again. The phone started to download the appropriate firmware.
Minutes in, I re-enabled the wifi for a faster download; downloading and updating the watch both succeeded. So apparently, only the initial negotiation required this workaround.
why?
It might be wifi bands, 5GHz (faster, but shorter range) vs 2.4GHz:
the iPhone 5 (2012) was the first one to support 5GHz wifi
the Apple Watch Series 6 (2020) was the first one to support 5GHz wifi, and the watch in question was a series 4 (2018)
]]>0admin<![CDATA[Posting notes]]>https://pronoiac.org/misc/?p=1632023-05-03T23:46:34Z2023-05-03T22:54:16ZI’ve long braindumped notes into a specific app, which has issues with, say, command line details and links; smart quotes can lead to really unpleasant surprises and breakage, for example. I’ve been spreading notes across other apps and locations, and it’s tripping me up when I reach for notes.
So, I might post some of my notes to my blog. They might be helpful to other people. Just having them tagged here might make them easier for me to find.
(to do: switch themes to one that displays tags)
]]>0admin<![CDATA[Hourly Dong, from Glass Onion]]>https://pronoiac.org/misc/?p=1412023-01-03T05:16:41Z2023-01-03T04:30:23Zabout
In the movie “Glass Onion”, there’s a recurring background chime: every hour, a resounding “dong!” with some chimes. Turning this into a ringtone sounded like fun.
what
Here’s the playable mp3 (I didn’t make the mp3, see below for the source):
And here’s the m4r version, usable as a ringtone on iPhones. It’s an aac / mp4 (audio-only) file.
how to use this on iPhones
This seems like something that should be easy and built-in, but it’s not. This is using Music, not iTunes, on a Mac.
To transfer the file: Download the m4r file, and open a Finder window for Downloads (or wherever you saved the file).
Plug your device in.
Open the General view in Finder for your device.
Drag and drop the “hourly dong” m4r file over to that Finder window.